負荷を生成する
KEDA ScaledObject の設定に応じてデプロイメントのスケーリングを観察するために、アプリケーションに負荷をかける必要があります。hey を使ってワークロードのホームページを呼び出すことで負荷をかけます。
以下のコマンドは、次のパラメータで負荷生成器を実行します:
- 同時に実行する3つのワーカー
- 各ワーカーが1秒間に5つのクエリを送信
- 最大10分間実行
~$export ALB_HOSTNAME=$(kubectl get ingress ui -n ui -o yaml | yq .status.loadBalancer.ingress[0].hostname)
~$kubectl run load-generator \
--image=williamyeh/hey:latest \
--restart=Never -- -c 3 -q 5 -z 10m http://$ALB_HOSTNAME/home
ScaledObject に基づいて、KEDAはHPAリソースを作成し、HPAがワークロードをスケールするために必要なメトリクスを提供します。アプリケーションにリクエストを送信したので、HPAリソースを監視して進捗を確認することができます:
~$kubectl get hpa keda-hpa-ui-hpa -n ui --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-ui-hpa Deployment/ui 7/100 (avg) 1 10 1 7m58s
keda-hpa-ui-hpa Deployment/ui 778/100 (avg) 1 10 1 8m33s
keda-hpa-ui-hpa Deployment/ui 194500m/100 (avg) 1 10 4 8m48s
keda-hpa-ui-hpa Deployment/ui 97250m/100 (avg) 1 10 8 9m3s
keda-hpa-ui-hpa Deployment/ui 625m/100 (avg) 1 10 8 9m18s
keda-hpa-ui-hpa Deployment/ui 91500m/100 (avg) 1 10 8 9m33s
keda-hpa-ui-hpa Deployment/ui 92125m/100 (avg) 1 10 8 9m48s
keda-hpa-ui-hpa Deployment/ui 750m/100 (avg) 1 10 8 10m
keda-hpa-ui-hpa Deployment/ui 102625m/100 (avg) 1 10 8 10m
keda-hpa-ui-hpa Deployment/ui 113625m/100 (avg) 1 10 8 11m
keda-hpa-ui-hpa Deployment/ui 90900m/100 (avg) 1 10 10 11m
keda-hpa-ui-hpa Deployment/ui 91500m/100 (avg) 1 10 10 12m
自動スケーリングの動作に満足したら、Ctrl+Cで監視を終了し、次のように負荷生成器を停止します:
~$kubectl delete pod load-generator
負荷生成器が終了すると、HPAが設定に基づいてレプリカ数をゆっくりと最小数まで減らすことに注目してください。
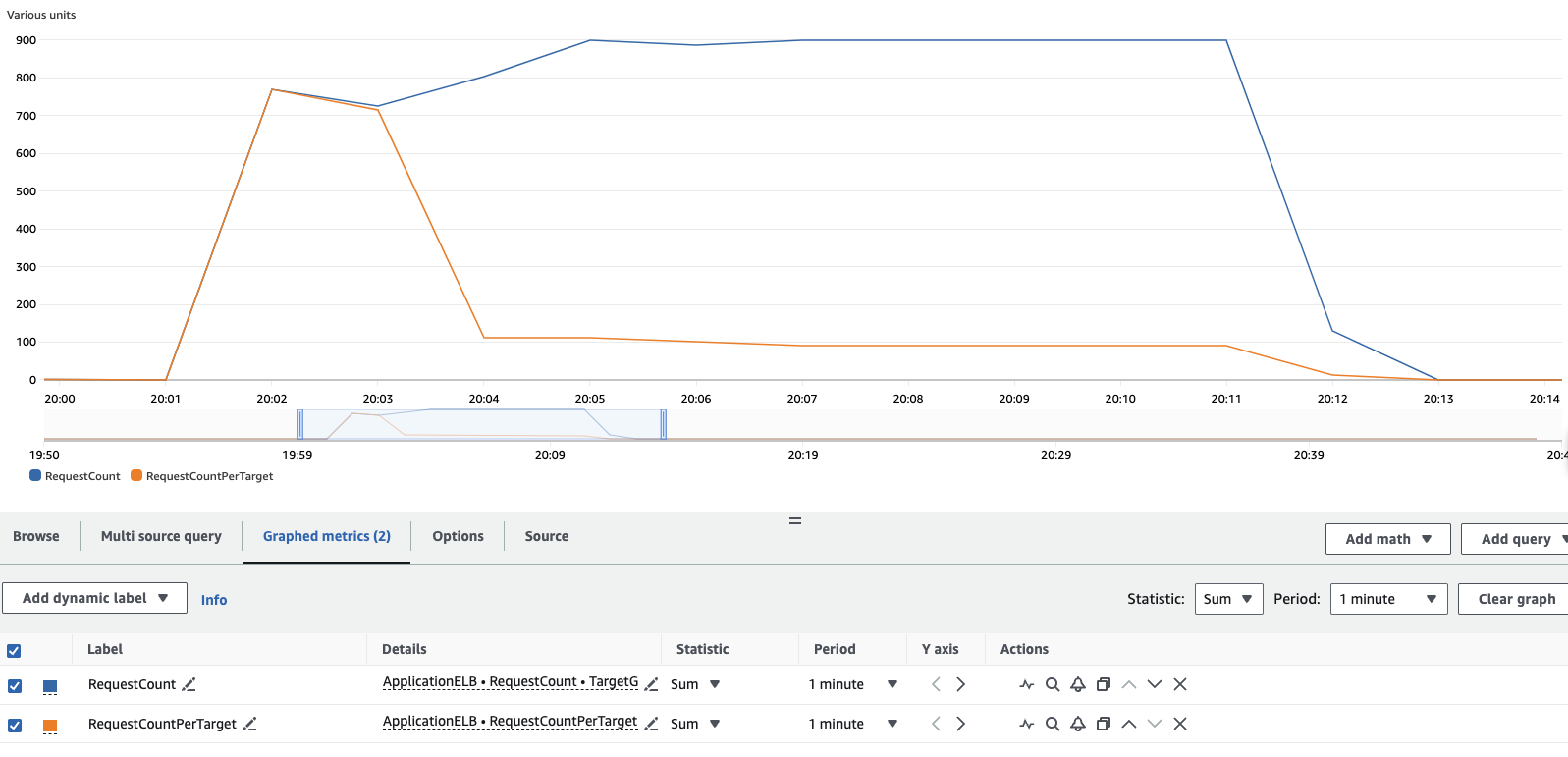
CloudWatchコンソールで負荷テストの結果を確認することもできます。メトリクスセクションに移動し、作成されたロードバランサーとターゲットグループのRequestCountとRequestCountPerTargetメトリクスを見つけてください。結果から、最��初はすべての負荷が1つのPodによって処理されていましたが、KEDAがワークロードのスケーリングを開始すると、リクエストがワークロードに追加された追加のPod全体に分散されていることがわかります。load-generatorポッドを10分間実行すると、以下のような結果が表示されます。